You are here
Redundant ethernet configuration with bonding and VLANs
Network hardaware failures often cause unnecessary downtimes of important services. This article describes a configuration that provides servers with redundancy, so that if a single switch, network cable or network adapter fails, the server remains reachable.
Prerequisites
It is assumed that the server has at least two network ports (otherwise there is no way to achieve redundancy). Note that if the server has just two ports, it usually means that they are provided by the same network controller. If the controller then fails, no redundancy can be provided, because both network interfaces will stop working properly. Therefore, this scenario will assume four network ports, two (eth0 and eth1) managed by the first controller and the other two (eth2 and eth3) by the other. That said, it should be straight-forward to modify the configuratrion provided here to servers with just two ports.
The operating system is assumed to be Debian Jessie and the network configuration is done via /etc/network/interfaces. The configuration described here should also work with sufficiently recent Ubuntu versions.
There should be two managed switches available, so that if one switch happens to fail, the other switch will still provide connectivity. The switches should be interconnected (so that traffic can flow between them) and both should be connected to an uplink (with the proper precautions to avoid loops) - the configuration of the switches is beyond the scope of this article. The switches do not need to support LACP or similar, since the solution here will work in active-bakup mode, i.e. it will only switch to a different port on failure, not use both ports simultaneously. The latter is also possbile, but then the switches must support LACP with both switches collaborating.
It is assumed that there are at least 2 VLANs that the server should be connected to: a public VLAN (which is also carried over the uplink) and a private VLAN (not carried over the uplink). This is generic enough that the solution in this article may be tailored to the individual circumstances in a straight-forward manner, but it should simple enough to be easily understood.
An important goal of the solution presented here is to make sure that if one wants to perform maintenance on a server by booting from an external medium, the administrator should not be required to perform this complicated network configuation ad-hoc to reach both VLANs, they configuration for simple maintenance should be straight-forward. Any additional VLANs that are available to the server will require a more involved configuration, however.
Switch configuration
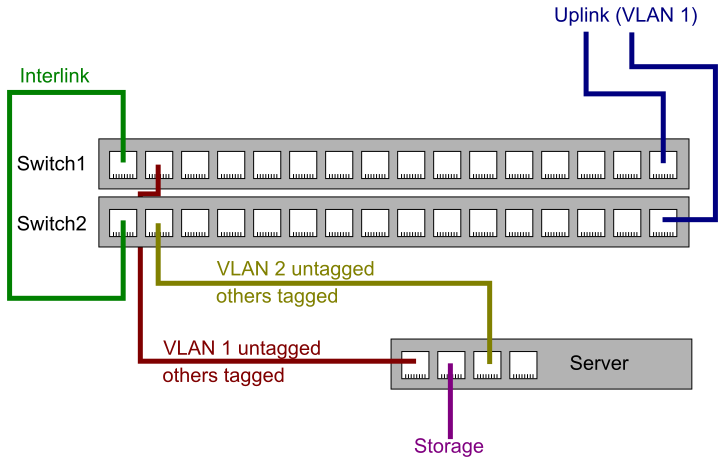
The server will be connected to one port in each switch. Both ports should be configured in hybrid mode, so that one VLAN is delivered as untagged traffic, and the rest is delivered as tagged. The first switch's port where the server is connected to should have the public VLAN (here ID 1) untagged and the private VLAN (plus any other additional VLANs) tagged. The second switch's port should have the private VLAN untagged and the public VLAN (plus any other additional VLANs) tagged.
This configuration implies that anything connected to the first port that isn't configured for VLANs (and just looks at and generates untagged traffic) will see the first port as a port where the public VLAN is reachable, and the second port as the port where the private VLAN is reachable.
The interlink between the switches should carry all VLANs, the uplink typically only the public VLAN.
Server hardware configuration
As mentioned before, the server is assumed to have four ports. The first port, eth0, should be connected to the first switch (i.e. the hybrid port with the public VLAN untagged), the third port, eth2, should be connected to the second switch (i.e. the hybrid port with the private VLAN untagged). The second and fourth ports are free for other usages; in this case it is assumed that the second port, eth1, is connected to external storage and the fourth port, eth3, is unused. But that is just an example.
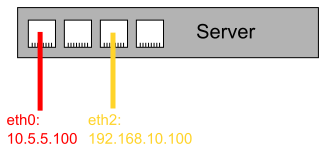
In this configuration, one could immediately configure the server to have its public IP directly on eth0 and its private IP on eth2 - and as long as there is no failure, this would work (without any redundancy, however). This makes this type of configuration really useful, because it makes the manual network configuration when booting from an external medium to perform maintenance very easy.
The following picture illustrates the network topology described here:
Server software configuration
In the following example, the server will have an internal bridge interface for the public VLAN (for virtual machines that should be accessible from the public network), whereas the private VLAN only has a regular interface without a bridge. Individual use cases may vary (no bridge required at all, or both VLANs should be bridged internally), but it's good to showcase both cases in one example (which itself is based on a real-world setup).
Redundancy will be provided by the ethernet bonding driver. Alternatively, one may also use the teaming driver (a more recent developement), which may be discussed in a future article.
Required packages
The following Debian packages will be required for this network configuration:
ifenslave: utilities and scripts to set up the bonding drivervlan: utilities and scripts to set up VLANsbridge-utils: utilities and scripts to set up the internal bridge
The configuration described here does not depend on the choice of the init system, all three init systems in Jessie will work.
Module parameters
The bonding driver has two ways of creating bonding devices: during initialization a certain number of (inactive) bonding devices with name bondX (X being an integer) will be created automatically. But it is also possible to dynamically create bond devices with arbitrary names at run time. In this article the latter method will be used. Unfortunately, the bonding driver creates a single bonding device by default, bond0. In order to suppress the default behavior (and only use the devices created by the configuration), one may create the file /etc/modprobe.d/bonding.conf with the following contents:
options bonding max-bonds=0
This is strictly speaking not necessary, since an unused bonding device is harmless - but it might be confusing, so it's better to explicitly disable it. Note that the option name max-bonds may be confusing here, since it doesn't specify the maximum number of bonding devices in general, but only the maximum number the driver should auto-create upon loading the module. (If the driver is compiled into a custom kernel and not present as a module, this has to be specified as bonding.max-bonds=0 in the kernel command line to achieve the same effect.)
Network configuration
In the following example, the network devices eth0, eth1 and eth2 will be configured. eth1 is trivial, since it is only supposed to connect to external storage in this example, therefore one uses something like the following in /etc/network/interfaces for eth1:
auto eth1 iface eth1 inet static address 192.168.20.100/24
The devices eth0 and eth2 are connected to the redundant switches, and their configuration is more involved:
- VLAN devices for the tagged VLANs have to be created: eth0.2 for the tagged private VLAN on eth0 and eth2.1 vor the tagged public VLAN on eth2. Note that VLAN ids are encoded via DEVICE.ID by default, so if the VLAN ids of a setup differ, the devices will be named differently.
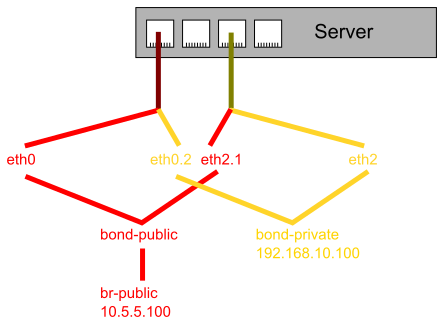
- The untagged network interface eth0 and the tagged interface eth2.1 will be combined into the bond interface bond-public. The name is arbitrary, but Linux limits network device names to 16 characters.
- The untagged network interface eth2 and the tagged interface eth0.2 will be combined into the bond interface bond-private.
- The bond interface bond-public will be added to a bridge br-public; the network configuration will not bridge this with other devices - in this example the bridge is for VMs, so the hypervisor (or similar) may add the devices of the virtual machines directly to this bridge.
First of all, any devices that is created in the network configuration (and not a bare physical device) has to be specified in the list of automatically activated devices, so one has to add the following line to /etc/network/interfaces:
auto eth0.2 eth2.1 bond-public bond-private br-public
This has the unfortunate side-effect that the scripts will complain on boot that eth0.2 and eth2.1 are already up (and on down that they were already removed). It will work, though, so it is best to simply ignore these warnings. Not specifying the devices in the auto line will not work, since ifupdown doesn't have a proper dependency mechanism between devices. Also, one could think that bond-public might not need to be specified here, since the bridge should automatically pull that in, but the bridge scripts only do that for VLAN devices, so it also has to be specified here. (There will be no warning about that, though, so if bond-public is not specified here, it will simply not be created.)
Next it is explicitly necessary to specify trivial lines for the VLAN devices, otherwise they won't be activated:
iface eth0.2 inet manual iface eth2.1 inet manual
If these lines are not specified for every VLAN device, they are not activated at boot (for unclear reasons). The manual keyword indicates that no network configuration action should be taken.
Now the bonding devices should be configured:
iface bond-public inet manual bond_slaves eth0 eth2.1 bond_primary eth0 bond_miimon 100 bond_mode active-backup iface bond-private inet static bond_slaves eth2 eth0.2 bond_primary eth2 bond_mode active-backup bond_miimon 100 address 192.168.10.100/24
Note that the address is only set for bond-private (since that is not going to be bridged), and for bond-public only the bonding options are configured (because it will be added to a bridge later). bond_mode active-backup makes sure that by default only a single interface is used and in case the interface fails, it will switch over to the other one. bond_primary determines the primary interface, so that once it's available again, it will switch back - otherwise the kernel would keep the last working configuration, so that even after recovering from a failure a single link would carry the entire traffic for both VLANs, which would not be optimal. bond_miimon 100 tells the kernel that it should detect failures by means of the hardware link state, and poll every 100 microseconds.
Finally, the bridge should be configured:
iface br-public inet static bridge_ports bond-public bridge_stp off bridge_maxwait 0 address 10.5.5.100/24 gateway 10.5.5.1
bridge_stp off is set here because it's just an internal bridge for VMs in this example; if this were to be used to bridge networks that could be in a loop, then this should be changed, obviously.
In the end, the /etc/network/interfaces file should look similar to this:
# This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto eth1 iface eth1 inet static address 192.168.20.100/24 auto eth0.2 eth2.1 bond-public bond-private br-public iface eth0.2 inet manual iface eth2.1 inet manual iface bond-public inet manual bond_slaves eth0 eth2.1 bond_primary eth0 bond_miimon 100 bond_mode active-backup iface bond-private inet static bond_slaves eth2 eth0.2 bond_primary eth2 bond_miimon 100 bond_mode active-backup address 192.168.10.100/24 iface br-public inet static bridge_ports bond-public bridge_stp off bridge_maxwait 0 address 10.5.5.100/24 gateway 10.5.5.1
The following graph visualizes how this configuration works (barring eth1):
In case of maintenance, when the server is booted from an external medium, the simplified network configuration (applying the IPs directly to eth0 and eth2, disregarding VLAN tagging) is visualized in this graph:
Further details
In the following some tangetial aspects of this problem will be discussed.
Failure monitoring
The kernel supports two methods of monitoring for link failures: the first just checks the link status (whether it's up or not according to the ethernet driver), while the second tries to get an ARP response.
The first (and default) method works really well if a network cable is pulled, a switch is rebooted (e.g. due to a firmware update), in many cases where the switch fails, and in some cases where the network controller fails. This is achieved by the setting bond_miimon 100, which specifies an interval of 100 milliseconds for checking whether the link is still up. (The value may be varied depending on the specific hardware, but 100 is a good starting point.) However, it could be that a switch (or a network adapter) fails, but the driver will still think the link is up. Therefore, the kernel alternatively provides ARP monitoring: in certain intervals it tries to perform an ARP lookup for a specific IP (which can be specified in /etc/network/interfaces via the bond_arp_ip_target setting), the intervals can be set via bond_arp_interval (in milliseconds). The ARP IP should be the IP of the managed switch or some other IP that is always online (otherwise it won't work!). Multiple IPs separated by commas may be specified. Please take a look at Documentation/networking/bonding.txt in the Linux kernel source tree for details. (Prepend bond_ to the options for them to work in /etc/network/interfaces.) Note that bond_miimon should not be set if ARP monitoring is used.
Unfortunately the kernel does not support ARP monitoring for bonding interfaces if they are added to a bridge. Therefore, only network link state monitoring can be used for the bridged case.
Debian Wheezy
Debian Wheezy is affected by Bug #699445, so that setting the primary bonding device doesn't work there. One can work around that by adding the following line to the interface configuration (and dropping bond_primary):
post-up echo PRIMARY_SLAVE > /sys/class/net/MASTER/bonding/primary
Fill in the values accordingly, e.g.
iface bond-public inet manual bond_slaves eth0 eth2.1 bond_miimon 100 bond_mode active-backup post-up echo eth0 > /sys/class/net/bond-public/bonding/primary
(Failovers should work regardless, but after recovery if a primary is not set, all traffic will go though the other device.)
Apart from that the configuration will work exactly the same as with Debian Jessie. In addition to the warnings one also sees in Jessie about bringing up each VLAN interface twice, some additional error messages will appear (they can be ignored, though).
Note though that the package that contains the scripts for the bonding driver is called ifenslave-2.6 in Wheezy or earlier, ifenslave is the new name under Jessie.
Bridges vs. VLANs
Important note: if you don't use bonding and add a physical device (e.g. eth0) directly to a bridge, then all VLAN-tagged traffic will also be carried over thar bridge. This means that having a setup where eth0 is part of a bridge br0, plus having a separate VLAN interface eth0.42 for VLAN-tagged traffic, will not work out of the box. For that to work, one needs to tell the kernel to not bridge frames from that interface that contain VLAN tags, so that the VLAN code can then process the frames and properly route them to the appropriate network interfaces.
At first glance, it might appears to be the case that the bonding setup described in this article would also require this. That is not the case, though: the bonding driver doesn't process VLAN-tagged traffic by default (unless there's a VLAN-tagged subinterface of the bond interface present), so that the bridge described in this article will never see VLAN-tagged frames in the first place. This makes settings that are required for the direct bridging of physical interfaces unnecessary in this case.
Summary
This article describes a possible configuration to provide redundancy for the network connectivity of a server, while at the same time making manual network configuration for quick maintenance really easy.
{kind=link}
{kind=link}
{kind=link}
- Log in to post comments